Lười như Haskell (Lazy evaluation)
11 May 2022
・
11 May 2022
・

1. Lazy evaluation vs Eager evaluation
Khi trình phiên dịch gặp một expression (biểu thức), nó sẽ đứng trước 2 sự lựa chọn
Evaluation là quá trình tính toán ra giá trị tận gốc của một mảng code. Giá trị tận gốc của 2 + 5 là 7.
Đa phần các ngôn ngữ lập trình đều chọn evaluate ngay lập tức và lưu kết quả vào bộ nhớ. Não mình cũng thường evaluate những chuyện đang xảy ra. Mình nói chuyện với một đứa bạn, nó bảo “nó ở cùng với mẹ của mẹ nó”. Trong đầu mình sẽ evaluate ra à, “nó ở với bà ngoại của nó”.
Cách evaluate ngay có tên gọi là Eager Evaluation. Tuy Eager Evaluation có những ưu thế riêng, nhưng trong trường hợp dưới đây thì có vẻ không hiệu quả lắm:
addOne(x, y) := x + 1
addOne(4/2, 10+8)
Thà giết thừa còn hơn bỏ sót, các ngôn ngữ sử dụng Eager Evaluation sẽ phải làm phép tính cho cả 4/2 và 10+8. Nhưng tính 10+8 ra cũng không để làm gì.
Đây là trường hợp mà Lazy Evaluation sẽ tỏa sáng. Gọi là lười vì Lazy Evaluation chỉ evaluate chính xác những giá trị cần dùng.
Tui biết ví dụ addOne trên nghe hơi lố, ai mà lại viết code dở ương như vậy? Nhưng mình có thể mường tượng ra nếu code có rẽ nhiều nhánh if/else thì mình sẽ thấy được độ chênh lệch lớn tới dường nào.
Haskell là gương mặt đại diện của Lazy Evaluation. Lazy evaluation và Haskell làm cho tui nghĩ đến bản chất lầy lội (thi thoảng xuất hiện) trong tui. Khi hoạt động theo cách này, interpreter đùn việc evaluation đến khi nào bị buộc phải làm thì mới vắt chân lên cổ mà chạy. Lắm lúc vậy mà lại tốt, khi bị dí sát nút thì nó chỉ tập trung chính vào giải quyết những việc bắt buộc cần làm, và tập trung làm cho nhanh.
2. The gifts of laziness
Nhờ cách làm này của Lazy evaluation mà mình có thể sử dụng các loại cấu trúc dữ liệu vô tận trong Haskell.
2.1 Working with infinite lists
Trong Haskell, mình có thể viết tập hợp vô hạn của các số dương có thể chia hết cho 15 như sau:
mulOf15 = [15, 30.. ]
Eager Evaluation chắc chắn sẽ không chịu nổi loại hình thể thao này. Tưởng tượng Java hay Python mà gặp cái list này thì sẽ miệt mài evaluate cho đến hơi thở cuối cùng… mà vẫn chưa xong.
Mình có mulOf15 của Haskell rồi đó, mình có thể xào nấu theo một số cách như sau:
take 5 mulOf15 –- output: [15,30,45,60,75]
take 1000 mulOf15 –- output: a list of the first 1000 elements in mulOf15
takeWhile (<100) mul15 –- output: [15,30,45,60,75,90]
Stream là 1 loại infinite data structure thường xuyên xuất hiện trong nhiều lĩnh vực như networking, lexical analysis, sound analysis, vân vân. Haskell tạo điều kiện thuận lợi để xử lý với những dữ liệu này.
2.2 Concise code
range(), zip() trong Python cũng vận dụng cách làm của Lazy Evaluation. range(0, 100) trong Python được lưu bằng dưới dạng range, thay vì 1 list dài liệt kê đủ từ 0 tới 100.
Mình còn có map(), filter() - những function kinh điển được tạo ra bởi combo của Lazy Evaluation và Functional Programming. Những hàm này không những làm gọn code trên bề mặt, mà còn tiết kiệm được bao nhiêu công sức parse và evaluate. Cũng vì lẽ đó mà được sử dụng rộng rãi tại rất nhiều ngôn ngữ khác.
Cũng nhờ sử dụng nhuần nhuyễn map() và filter() trong Haskell mà khi code, tui thường nghĩ đến cách biến đổi của dữ liệu hơn, thay vì phải suy nghĩ từng bước mệnh lệnh cho chương trình.
2.3 Data transformation
Ví dụ: mình có function doubleMe dùng để nhân đôi mọi giá trị trong list.
- Input: numList = [1, 2, 3, 4]
- Output: [2, 4, 6, 8]
Nếu viết theo cách imperative programming, tui chọn Python, mình sẽ viết thế này:
def doubleMe(numList):
output = []
for num in numList:
output.append(num*2)
return output
* Nếu mình muốn viết bằng Python one liner cũng được thôi nhưng tui muốn trình bày theo cách viết của imperative.
Còn Haskell trong functional programming sẽ viết như sau:
doubleMe numList = map (\num -> num*2) numList
Hơi khác nhau một xíu rồi, nhưng nếu mình muốn gọi cái doubleMe này 3 lần thì mọi chuyện lại rẽ hướng xa hơn:
Khi một ngôn ngữ imperative như Python chạy doubleMe(doubleMe(doubleMe([1, 2, 3, 4]))), code sẽ xử lý từ trong ra ngoài (phải sang trái). Mỗi lớp trong được evaluate xong thì một copy mới lại được trả về. Cụ thể hơn, doubleMe3 xử lý cái list này 3 lần, 1 iteration mỗi lần xử lý => tổng cộng là 3 lần iteration.
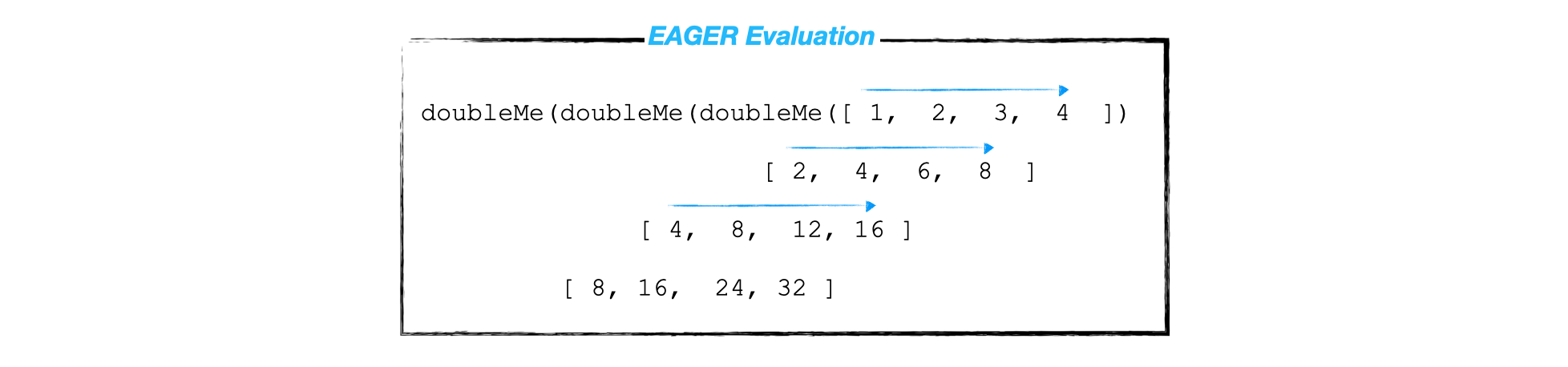
Vì lười, nên khi gặp doubleMe3 = doubleMe $ doubleMe $ doubleMe [1, 2, 3, 4], Haskell gửi thẳng cả đống thông tin này vào heap.
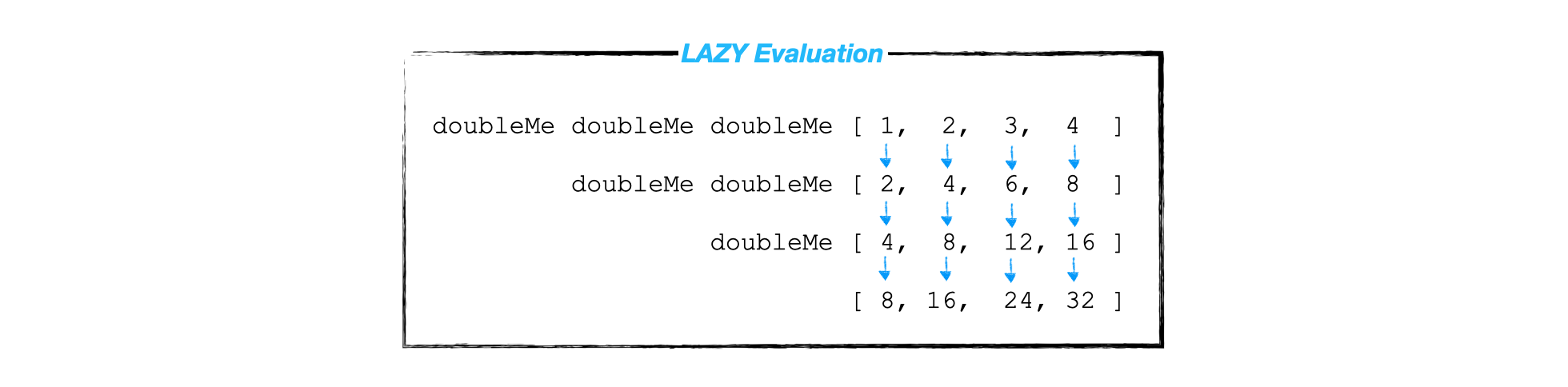
Khi code bị gọi, Haskell mới đủng đỉnh evaluate theo thứ tự: ngoài vào trong (trái sang phải).
- Anh
doubleMengoài cùng là anh cả. - Anh cả bị sẽ gọi anh hai
doubleMengay bên trong: “double cái cái số 1 này cho tao coi”. Anh hai gọi tiếp anh ba. - Anh ba là út không còn sai ai được nữa, đành phải tính: doubled 1 - là 2 trả lại cho anh hai, 2 trả lại 4, 4 trả lại 8.
Cứ thế, với từng con số trong list anh cả sẽ hò hét cho mấy đứa em làm. Toàn bộ chỉ dùng 1 iteration.
3. How does laziness work?
Haskell lười theo 2 nguyên tắc sau:
- Evaluate at most once
- Evaluate only when needed
3.1 Evaluate at most once
Đã lười thì mình lười cho tới. Thông thường parser sử dụng Abstract Syntax Tree (AST) để lưu trữ thông tin. Còn Haskell vận dụng Graph để tiện xài lại kết quả evaluate của các expression giống nhau.
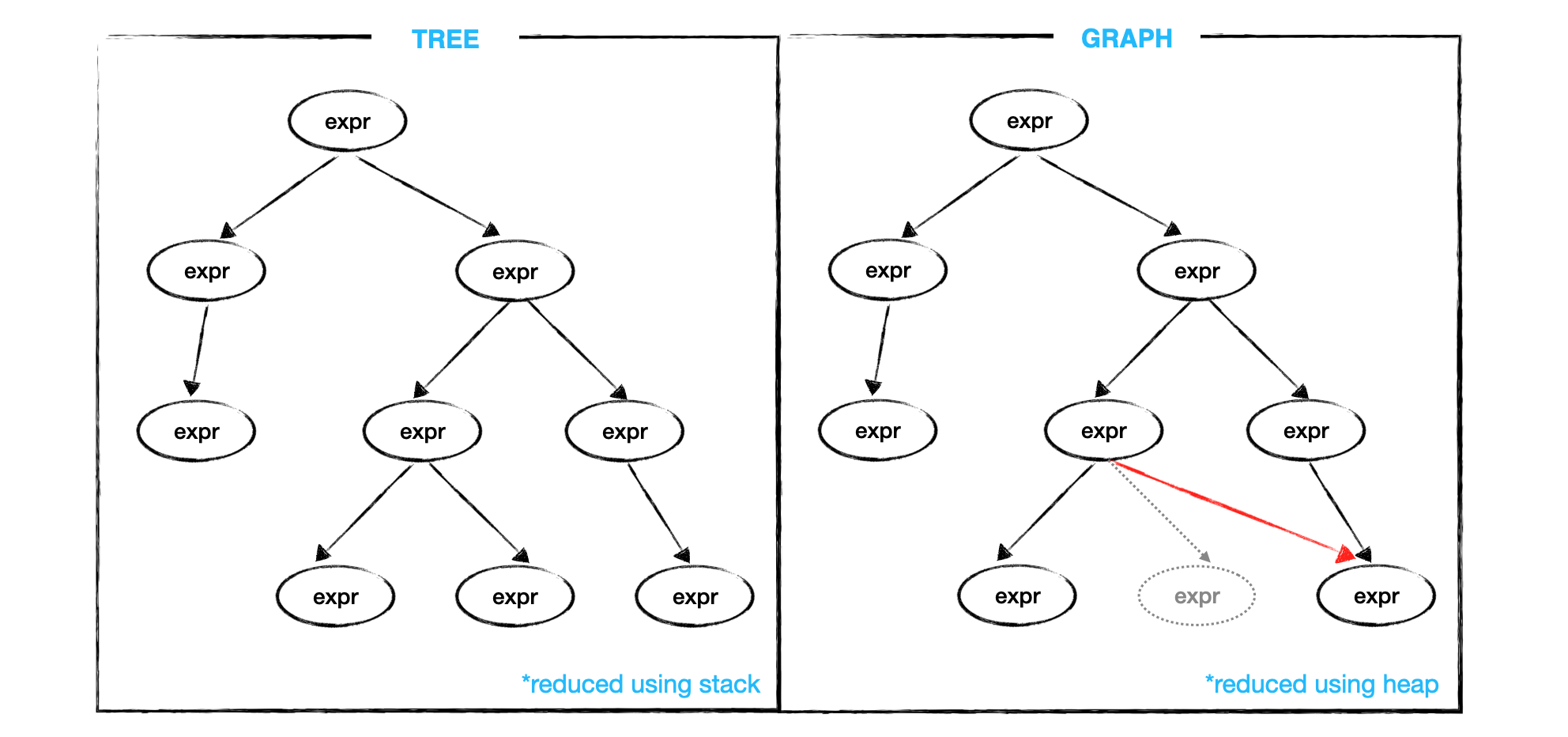
3.2 Evaluate only when needed
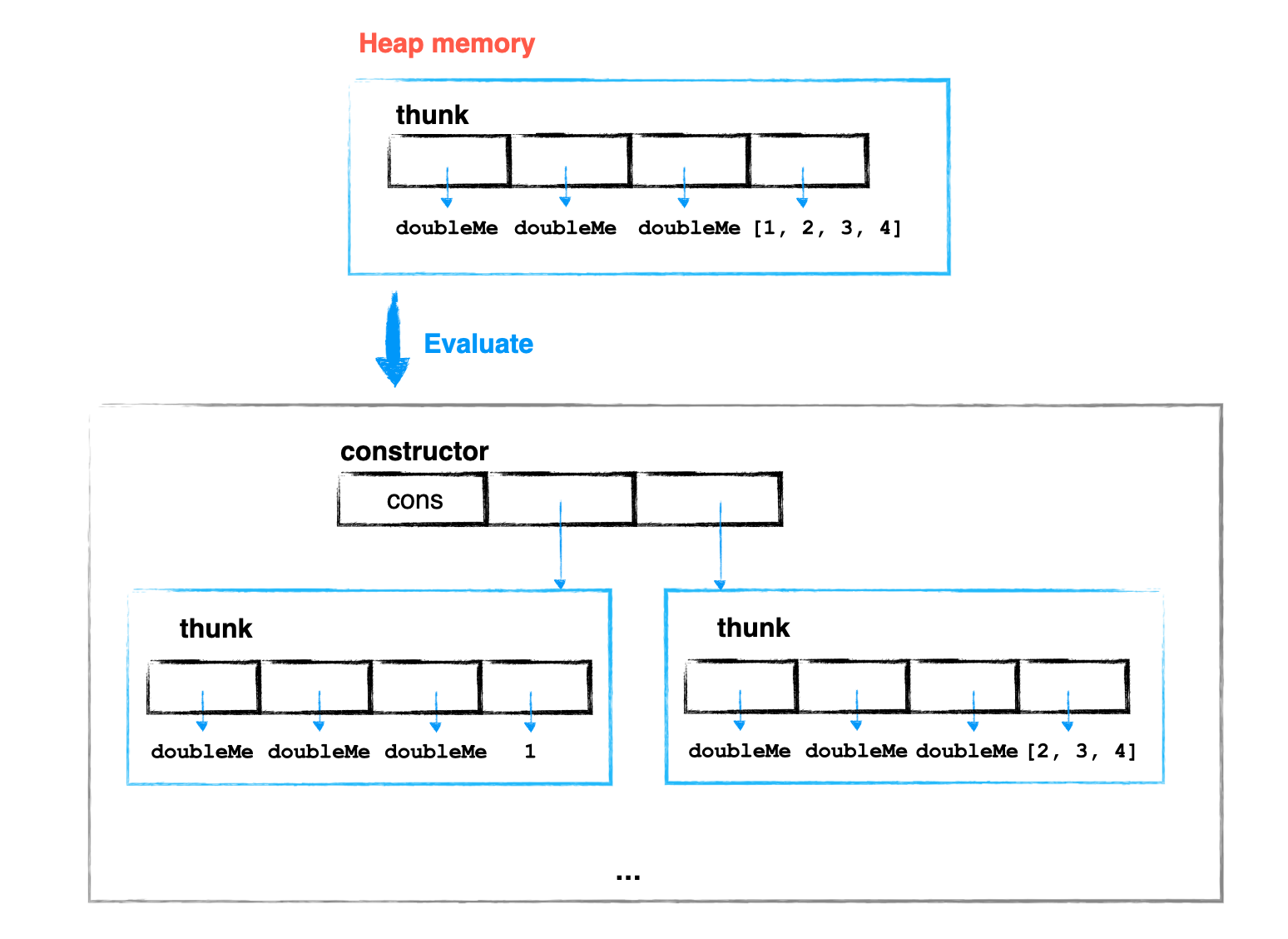
Khi parse, Haskell sẽ tạo ra một cấu trúc dữ liệu gọi là thunk. Thunk nằm trên heap memory và được dùng để chứa tất cả các thông tin cần dùng để evaluate expression đó.
Khi được triệu hồi để evaluate, trình phiên dịch sẽ dùng thông tin trên thunk để tính toán giá trị đích thực của expression đó và cập nhật thẳng lên thunk luôn.
4. Conclusion
Để ý thấy nhiều thunk được tạo ra trên heap thế kia thì chắc bạn cũng đoán được lazy evaluation tốn cũng kha khá bộ nhớ, từ đó khó mà đo lường được chính xác công suất bộ nhớ của chương trình. Ngoài nha, anh nhà Garbage Collector chắc cũng phải đô con lắm để dọn được hết cái mớ này.
Đây là một trong số nhiều thông tin tui gom góp được sau 3 tháng nếm mùi Haskell. Dù tui không đi theo Haskell và pure functional programming (xin lỗi vì plot twist :3), nhưng có thể nói Haskell đã cho tui một cách nghĩ mới mẻ trong lập trình. Từ giờ khi code mà thấy những mảnh ghép đến từ functional programming thì mình cũng biết bản chất lười mà khôn của tụi nó.

Nguồn tham khảo:
- https://takenobu-hs.github.io/downloads/haskell_lazy_evaluation.pdf
- http://learnyouahaskell.com/
- http://www.cs.umd.edu/class/spring2019/cmsc388F/lectures/laziness.html
- https://mmhaskell.com/blog/2017/1/16/faster-code-with-laziness